Cookieless tracking: what it is and how to implement it
Cookieless tracking is a method that gathers user data without relying on browser cookies. Instead, it uses methods like server-side tracking, first-party data, fingerprinting, and contextual targeting to understand behavior while ensuring privacy compliance. This approach helps businesses adapt to stricter regulations, improve data accuracy, and reduce dependence on third-party cookies.
In this blog post, we'll break down the concept of cookieless tracking, explain why it's essential, and provide tips on using it in your next marketing campaign. Take a few moments to put aside everything else you're working on - by discovering tracking without cookies, you may find new insights about your target audiences that will ultimately allow you to make smarter business decisions. Let's dive in!
What are cookies?
Cookies are small text files containing bits of data used to identify a user's computer while browsing a network. Certain cookies are designed to recognize individual users and enhance their web experience.

Why are cookies necessary?
Сookies make browsing the web a more seamless and unique experience for users.
Here are some reasons why cookies are important and why they exist:
- Authentication. Cookies allow websites to remember if a user is logged in or not. This means that users don't have to enter their login credentials every time they visit a website.
- Personalization. To remember a user's preferences, such as their language or font size.
- Shopping carts. When shopping online, cookies can be used to remember what items are in a user's shopping cart, even if the user leaves the website and returns later.
- Analytics. To track how users interact with a website: what buttons they click on or not, etc. This information can be used to improve the website's design and functionality.
- Ad targeting. Cookies can be used to track a user's browsing history and interests, which allows advertisers to show more relevant ads.
Cookies exist to enhance the user experience on websites and to enable website owners to collect data that can be used to improve their services and marketing efforts. While there are some privacy concerns related to cookies, which we'll describe further, they are an essential part of the modern web.
Cookie tracking issues
Cookies help track user behavior, personalize content, and support ad targeting. But they also come with serious concerns.
Privacy issues. Cookies can help track users across multiple websites. This helps advertisers build detailed profiles, which many users find intrusive.
Security risks. Some cookies store sensitive data, like login tokens or payment-related info. If stored on the browser, this data can be accessed by third-party scripts, browser extensions, or malicious programs running on the user’s side.
Malicious cookies. Though rare, cookies can be used to deliver malware to a user’s device.
Browser restrictions. Safari and Firefox are now blocking third-party cookies by default. Safari’s Intelligent Tracking Prevention (ITP) limits all commercial first-party cookies to 1–7 days. That means even if someone returns after 24 hours, Safari may treat them as a brand-new user.
If your site sells high-ticket items or requires multiple visits before conversion, this makes tracking nearly impossible. You can compare the difference by checking how many returning users show up in Safari vs Chrome inside GA4.

How analytics and marketing platforms try to overcome the use of cookies
GA4 is marketed as privacy-focused, and it is meant to function with or without cookies. GA4 can cover the data collection gaps as the world grows less reliant on cookies by utilizing machine learning and statistical modeling.
With browsers such as Safari and Firefox restricting third-party cookies, you can configure Google Analytics 4 to depend on first-party cookies by transitioning to server-side GA4 tracking. Mapping tagging server URL with a custom domain establishes 1st party cookies, which are more dependable and have a longer lifespan than 3rd party cookies.
Hosting server-side setups through platforms like Google Cloud can get costly and complicated. That’s why many marketers prefer managed services like Stape, which offers a free tier for up to 10,000 requests and paid plans starting at $20/month. You skip infrastructure work and start tracking right away.
You can set up GA4 tracking without utilizing any cookies, be it 1st or 3rd party, by using Stape's Advanced GA4 tag. This allows for purely server-side GA4 tracking.
And as for the Facebook solution - Facebook Conversions API and Conversions API Gateway - it can be said that besides cookies, it relies on user data. With the help of user parameters you send together with FB CAPI events, FB will match events to users in their database. As a result, you will have more reliable data and do not rely on cookies at all. To prevent the use of FB cookies, you should configure FB tracking exclusively on the server-side.
For example, let’s say you’re a home improvement brand. You used to buy third-party audience data about people who visit DIY blogs, then retarget them across platforms using cookies.
In a cookieless setup, this won’t work anymore. If someone visits your site without logging in or giving consent, you can’t retarget them one-to-one. That’s why platforms like GA4 or Facebook CAPI now rely on server-side setups
Why marketers are shifting to cookieless tracking
Three things changed the way tracking works:
Consumers started demanding more privacy and control. They don’t want to be tracked across the internet without knowing it.
Browsers and tech companies like Apple and Google responded by adding restrictions and phasing out third-party cookies.
Marketers now need new ways to measure performance and personalize content without relying on third-party data.
What does cookieless mean?
Cookieless means collecting user data without relying on cookies.
Third-party cookies are used to track users' activities across websites, so later the data is sent directly to platforms like Google Analytics or Meta.
This method is called ‘web tracking’.
Web tracking often results in lost data, as some events are not being registered due to browsers' privacy restrictions or ad blockers.
Cookieless tracking works without storing user data in cookies.
Instead of saving identifiers like user ID or session ID in the browser, this data is stored in a secure backend or passed through the cloud server directly.
Tools like server Google Tag Manager (sGTM) can help send events without relying on cookies, using alternatives like URL parameters or external ID systems.
This setup avoids cookie restrictions and improves tracking consistency.
How does cookieless tracking work?
Cookieless tracking works based on identifying and tracking users without relying on cookies, which are traditionally used to store user data on their device. Instead, it uses alternative methods like device fingerprints, server-side tracking, and other technologies to gather and process data.
With server-side tracking, the tracking code is executed on the server rather than on the user's browser. This means that the user's device does not need to store any tracking data, and the tracking is done entirely on the server side.
Server-side tracking can be implemented in several ways, including:
- Event tracking: Events such as page views, clicks, and form submissions can be tracked on the server side. The tracking data can then be stored in a database or sent to a third-party analytics service.
- Server log analysis: Server logs contain information about each request made to a website, including the user's IP address, user agent, and other data. This information can be analyzed to track user behavior and generate reports on website traffic.
- API tracking: APIs can be used to track user behavior on third-party platforms, such as social media or mobile apps. The tracking data can be sent to the server and processed using server-side code.
Stape has a full list of platforms that support server-side tracking.
To implement server-side tracking without cookies, it's essential to configure each tracking vendor purely on the server side. This approach ensures tighter control over the information each vendor sets and collects.
For instance, the default setups of platforms like Google Analytics 4, Facebook, and TikTok work with only web (client-side) tracking, but this often leaves gaps in the data. To get accurate and complete insights, most businesses adopt a hybrid setup that combines web and server-side containers. In GA4, this approach is especially relevant as more marketers turn to cookieless tracking GA4 to reduce reliance on browser cookies. While web pixels can still gather data, server-side tracking helps overcome data loss caused by ad blockers, ITP, and other browser restrictions - making it the key to reliable, privacy-compliant analytics. You can also pair a cookieless setup with marketing mix modeling to plan budgets and forecast results.
With pure server-side tracking, you'll have a singular data stream that sends user and event data to the server-side container, which could be, for instance, webhooks from your CMS or CRM. Subsequently, within the server-based Google Tag Manager container, you determine what information gets relayed to your analytics and marketing platforms.
Main steps of the implementation of cookieless tracking
Cookieless tracking can look different depending on your setup, but the core principles stay the same.
Here’s what most cookieless configurations include:
Skip cookies completely
Don’t rely on browser cookies to store user or session data.
Instead, use a backend store like Stape Store. For cookieless GA4 tracking, this means saving values like client_id, session_id, and first_visit directly in your backend.
Create your own identifiers
To link browser events with stored data, you need a consistent identifier.
This can be done with fingerprinting or Stape User ID.
Store click IDs in an external database
Capture important click IDs like fbclid from the URL on the landing page, and save them in your backend. This helps platforms like Meta match conversions to the right ad clicks, even without cookies.
What about hashed IDs?
Some platforms use hashed identifiers when cookies are blocked. This usually means combining IP, user agent, and URL to generate a unique ID that’s stored server-side.
This method can work, but it’s a one-way system. You can’t enrich or update user profiles later. Tools like server GTM and Stape Store give you more flexibility to manage identifiers, connect events, and keep user data compliant without being locked into hashing.
Comparison of cookieless tracking methods by criteria
| Server-side tracking | Data layer | Session storage | Local storage | |
| Use cases | Store sensitive data for a long time | Real-time data storage | Track and temporary store events (page views, clicks) | Track events persistently |
| Data durability | As long as needed (depends on server configuration) | As long as the user is on the page | As long as a session runs | Until data is cleared manually |
| Data size limits | No limits | It is not fixed, but it is used for small datasets | 5 MB per origin | 5 MB per origin |
| Location | Server-side (a server that you own and control) | Client-side (client’s browser) | Client-side (client’s browser) | Client-side (client’s browser) |
| Security | The most secure compared to other methods | Vulnerable to client-side attacks (e.g. Cross-Scripting) | Vulnerable to client-side attacks (e.g. Cross-Scripting) | Vulnerable to client-side attacks (e.g. Cross-Scripting) |
Cookieless tracking methods explained
Server-side tracking: secure and precise data tracking
The benefit of server-side tracking is that all users' data is sent firstly to the server and then transferred to tracking platforms (like Google Tag Manager) and third-party vendors (e.g., Google Analytics). Such data processing and distribution methods help bypass ad blockers and browser restrictions. Server-side tracking also helps comply with GDPR and CCPA regulations.
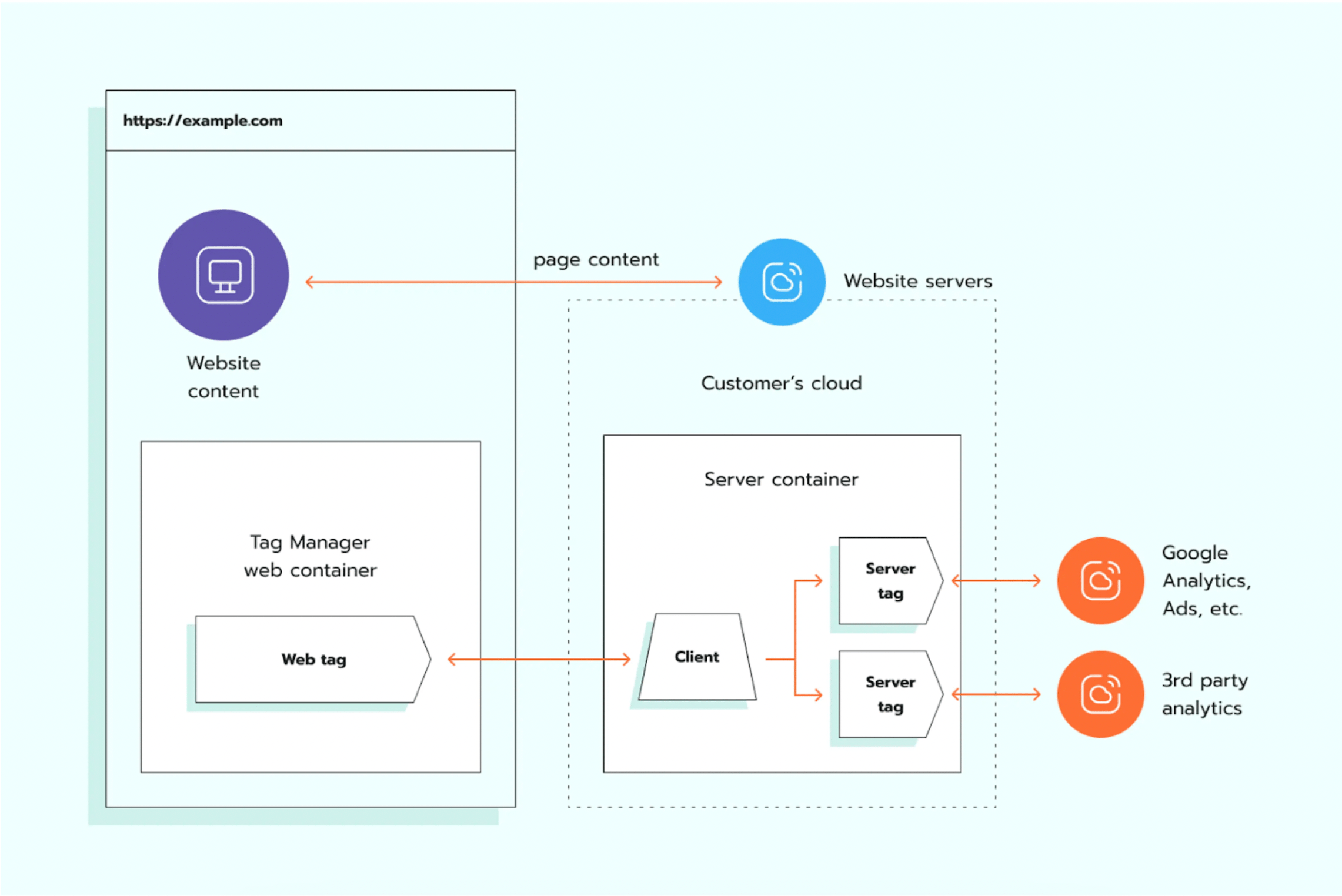
Another benefit of server-side tracking is the higher control over collected data, as all the data is processed on your own servers rather than handled on the client side (users' browsers). Unlike client-side methods such as Local and Session storage, this approach offers enhanced security, making it a better choice for managing sensitive information.
How to start using server-side tracking
Firstly, you need to choose a hosting provider for the server GTM container. One popular option is using the Google Cloud Platform. We recommend considering Stape as a hosting provider and solution hub for server GTM. Stape has many advantages over GCP, which businesses of all sizes and types can benefit from.
| Stape | Google Cloud Platform |
| Free plan for 10,000 requests per month | Price starts at $120/month |
| Wide range of plans for high-traffic websites to avoid overpaying ($20 - $300/month) | For websites with higher traffic, the price can increase to $240-$300 per month |
| No additional costs if you have a paid plan | Logs will cost an additional $100 for 500,000 requests |
| Variety of solutions for sGTM (power-ups, tags, variables) |
Secondly, you need to create and configure a server-side container. If you have already used web GTM, you probably won’t face difficulties setting it up as the interface and functions are similar.
Then you can add any solutions, and power-ups and set up any tracking you need for your business.
Data layer: effective real-time data storage
The data layer as a cookieless solution works for cases when you need to collect lightweight data (like UTM-parameters data) that doesn't require extra security. Otherwise, we recommend using server-side tracking, which is better for large datasets and sensitive data.
The data layer is a method for temporarily storing real-time data. When a user visits your website, you can capture data from them and temporarily store it in the data layer. This happens before consent is granted. After the user's content (clicking on cookie consent banners), you transfer data to analytics tools like Google Analytics 4.
Using a data layer for cookieless tracking has a disadvantage compared to server-side tracking or local storage - the data is stored as long as the session runs. However, the data gathered can be accessed by tags and scripts you use.
How to start using the data layer
You need to initialize the data layer (if it doesn't exist yet).
| Related: End-to-end guide on data layer in Google Tag Manager - you will find this article useful if you haven't worked with the data layer yet. |
Then, you need to set up capturing data (let's say, UTM parameters from URL) and temporarily store them in the data layer you created. Once the user grants consent (like a trigger), the script should find the necessary data and transfer it to the analytics tool.
You need to write the script independently or ask a developer to do it.
Session storage: for specific data within a session
Session storage is a good method if you want to collect data that will be stored only for the duration of the session. Such type of data includes page views or button clicks.
One advantage of session storage is high privacy; the data is cleared once the user stops a session. However, this feature prevents you from storing data for a long time, like with server-side tracking or local storage.
How to start using session storage
The web storage API lets you interact with the browser's session storage. To apply this method, you need to use a script. The JavaScript code should first retrieve or initialize the count of some event (e.g., page view or click to a button), then increment the event count and store it in session storage.
Local storage: track persistent data across sessions
Unlike session storage, local storage can track and store data across multiple sessions. However, it is better to use this method for non-sensitive data.
Local storage is usually used to track and store data like page language or layout to determine user preferences on your website, track the number of transactions, or count events (clicks, page views). It is also an effective way to find out the number of returning users (with the help of a User ID); such a feature can be useful if you build brand recognition.
How to start using local storage
Local storage, like session storage, is part of the web storage API, so you can interact with it using the API. The flow is similar to session storage; with local storage, you need to use the script to gather and store data locally.
7 Key Cookieless tracking solutions for 2026
The following list focuses on tools that professionals use to keep attribution, analytics, and budget decisions working with less cookie data. Use it as a shortlist when you pick what to add on top of your current setup.
- Stape
- Ruler Analytics
- Google’s Meridian
- Meta’s Robyn
- TWIPLA
- Matomo
- Fathom
Stape
Stape is a cookieless tracking option that adds a cloud server layer to your setup. Events still start on the website, but they pass through the cloud server before going to analytics and ad platforms. This helps keep signals stable.
Stape gives you control over what data gets sent, and where it goes. You can enrich events with backend details, for example order status, refund info, product margin, or a CRM customer ID. This keeps attribution and reporting consistent when browser tracking drops.
Ruler Analytics
Ruler focuses on attribution when user-level identifiers and cookies are not reliable. It combines deterministic measurement where possible with cookieless methods like probabilistic attribution and marketing mix modeling. This approach helps you keep a view of which channels and campaigns drive revenue, even when you cannot rely on a full click-path for every user.
A practical use case is budget decisions across channels when conversions happen after multiple visits. Ruler can use signals such as impressions and other platform data to model impact when direct tracking is limited. It is a fit if attribution is your main pain and you need reporting that stays stable as browser limits increase.
Google’s Meridian
Meridian is a marketing mix modeling approach designed to measure how marketing activity influences outcomes without depending on cookies. It works by modeling channel impact from historical performance and media inputs, rather than user IDs. This makes it useful when you need a channel-level view that stays available even when tracking data is incomplete.
It is a fit if you want a measurement layer that can cover channels that never had strong cookie tracking, like offline media. It also helps when you need a planning method for spend allocation across channels. Treat it as a modeling layer that sits next to your tracking setup, not a replacement for event tracking.
Meta’s Robyn
Robyn is another marketing mix modeling tool that focuses on measuring ad impact over time using machine learning. It is designed for teams that have enough historical data to model results across channels and campaigns. It helps answer “what moved results” without needing user-level cookies.
Robyn makes sense when you want an independent modeling check beside platform reports. It is also helpful for longer sales cycles where direct attribution becomes fragile. You still need clean inputs, so the quality of your spend and outcome data matters more than your cookie coverage.
TWIPLA
TWIPLA is a cookieless web analytics tool that includes heatmaps and session recordings. It helps you see how visitors move through key pages when cookies are limited, so you can still spot friction points in your funnel.
Use TWIPLA when you want more than traffic numbers. It gives you behavior data you can base your marketing decisions on.
Matomo
Matomo is a full analytics platform that supports tracking without cookies. It covers the basics like page views, sources, and events, without relying on cookies for identification.
Choose Matomo when you want a self-owned analytics baseline that stays consistent as cookie rules tighten. It works well next to server-side tracking, because it focuses on on-site reporting, not ad platform attribution.
Fathom
Fathom is a privacy-focused web analytics tool built around first-party measurement. It is designed to give you core site insights like traffic sources and engagement. It is a fit for teams that want clean website analytics with a minimal data footprint.
Fathom works well as a replacement for cookie-heavy on-site analytics when you mainly need content and acquisition reporting. It is also useful when legal and privacy expectations shape what you can collect. Pair it with a MMM tool if you need deeper campaign measurement.
FAQs
Do you need consent for cookieless tracking?
Often, yes.
In the EU, GDPR rules require user consent if you collect personal data, even if you don’t use cookies. That includes IP addresses, emails, and any identifiers that can be linked to a person.
Some countries like Denmark, Belgium, and Germany ban all cookies (even functional ones) without explicit consent. These stricter rules are expected to expand across the EU under the upcoming ePrivacy Regulation.
In the US, rules vary by state. Some, like California’s CCPA, focus more on transparency and giving users the option to opt out.
Always check with your legal team to understand what applies in your region and how your setup handles user data.
What should marketers do about cookieless tracking?
As cookies become less reliable, marketers need a new approach to collect data and measure results.
Here’s what to focus on:
- Don’t rely only on browser cookies for tracking.
- Use first-party data where possible, and store it outside the browser.
- Set up server-side tracking to control how data is collected, processed, and shared.
- Focus on meaningful signals directly from your site, not from third-party scripts or networks.
- Make sure your setup complies with local privacy laws.
Are tracking cookies illegal?
Not exactly, but using them without proper consent is.Laws like GDPR require websites to obtain explicit permission before using most cookies, especially those used for advertising or cross-site tracking.
Does deleting cookies stop tracking?
Not completely.
It removes data saved in the user’s browser, but tracking can still happen in other ways, like using data sent through the website’s server.
That’s why many marketers now use both browser and server tracking to keep their data accurate and complete.
Conclusion
So there it is – an overview of how cookieless tracking works and what it can do for your marketing campaign. We hope this blog post has inspired you to explore tracking without cookies and use that knowledge in your next marketing decision. With Stape's help, you can tap into your audience on a level they never dreamed of before.
So don’t wait. Start using cookieless tracking today and see how it changes your business.
Check your website’s tracking health
Click on Scan your site to use our Website Tracking Checker and get a detailed report on how to fix tracking issues and boost performance.

Comments