Cookieless tracking: wat het is en hoe je het implementeert
Cookieless tracking is een methode waarmee gebruikersdata wordt verzameld zonder te vertrouwen op browsercookies. In plaats daarvan worden methoden zoals server-side tracking, first-party data, fingerprinting en contextuele targeting gebruikt om gedrag te begrijpen en tegelijkertijd privacycompliance te waarborgen. Deze aanpak helpt bedrijven zich aan te passen aan strengere regelgeving, de nauwkeurigheid van data te verbeteren en de afhankelijkheid van third-party cookies te verminderen.
In deze blogpost leggen we het concept van cookieless tracking uit, lichten we toe waarom het essentieel is, en geven we tips over hoe je het in je volgende marketingcampagne kunt toepassen. Neem even de tijd om alles wat je op dit moment doet opzij te leggen – door tracking zonder cookies te ontdekken, kun je nieuwe inzichten over je doelgroepen opdoen die je uiteindelijk helpen slimmere zakelijke beslissingen te nemen. Laten we erin duiken!
Wat zijn cookies?
Cookies zijn kleine tekstbestanden met stukjes data die worden gebruikt om de computer van een gebruiker te identificeren tijdens het surfen op een netwerk. Bepaalde cookies zijn ontworpen om individuele gebruikers te herkennen en hun webervaring te verbeteren.

Waarom zijn cookies noodzakelijk?
Cookies maken het surfen op het web een vloeiendere en persoonlijkere ervaring voor gebruikers.
Hier zijn enkele redenen waarom cookies belangrijk zijn en waarom ze bestaan:
- Authenticatie. Cookies stellen websites in staat te onthouden of een gebruiker is ingelogd of niet. Dit betekent dat gebruikers hun inloggegevens niet elke keer hoeven in te voeren wanneer ze een website bezoeken.
- Personalisatie. Om de voorkeuren van een gebruiker te onthouden, zoals taal of lettergrootte.
- Winkelwagens. Bij online winkelen kunnen cookies worden gebruikt om te onthouden welke artikelen in de winkelwagen van een gebruiker zitten, zelfs als de gebruiker de website verlaat en later terugkeert.
- Analyse. Om bij te houden hoe gebruikers met een website omgaan: op welke knoppen ze wel of niet klikken, enzovoort. Deze informatie kan worden gebruikt om het ontwerp en de functionaliteit van de website te verbeteren.
- Advertentietargeting. Cookies kunnen worden gebruikt om de browsegeschiedenis en interesses van een gebruiker bij te houden, waardoor adverteerders relevantere advertenties kunnen tonen.
Cookies bestaan om de gebruikerservaring op websites te verbeteren en websitebeheerders in staat te stellen gegevens te verzamelen die kunnen worden gebruikt om hun diensten en marketinginspanningen te verbeteren. Hoewel er enkele privacyzorgen zijn rondom cookies, die we verderop beschrijven, zijn ze een essentieel onderdeel van het moderne web.
Problemen met cookie tracking
Cookies helpen gebruikersgedrag bij te houden, content te personaliseren en advertentietargeting te ondersteunen. Maar ze brengen ook ernstige problemen met zich mee.
Privacykwesties. Cookies kunnen helpen gebruikers op meerdere websites te volgen. Dit helpt adverteerders gedetailleerde profielen op te stellen, wat veel gebruikers als opdringerig ervaren.
Beveiligingsrisico's. Sommige cookies slaan gevoelige gegevens op, zoals inlogtoken of betalingsgerelateerde informatie. Als deze gegevens in de browser worden opgeslagen, kunnen ze worden benaderd door scripts van derden, browserextensies of kwaadaardige programma's die op het apparaat van de gebruiker draaien.
Kwaadaardige cookies. Hoewel zeldzaam, kunnen cookies worden gebruikt om malware op het apparaat van een gebruiker te plaatsen.
Browserbeperkingen. Safari en Firefox blokkeren nu standaard third-party cookies. Safari's Intelligent Tracking Prevention (ITP) beperkt alle commerciële first-party cookies tot 1–7 dagen. Dat betekent dat Safari iemand die na 24 uur terugkomt mogelijk als een gloednieuwe gebruiker beschouwt.
Als je site dure artikelen verkoopt of meerdere bezoeken vereist voor conversie, maakt dit tracking vrijwel onmogelijk. Je kunt het verschil zien door te vergelijken hoeveel terugkerende gebruikers er in Safari versus Chrome in GA4 verschijnen.

Hoe analytics- en marketingplatforms proberen het gebruik van cookies te overbruggen
GA4 wordt gepromoot als privacygericht en is bedoeld om te functioneren met of zonder cookies. GA4 kan de hiaten in dataverzameling opvangen naarmate de wereld minder afhankelijk wordt van cookies, door gebruik te maken van machine learning en statistische modellering.
Nu browsers zoals Safari en Firefox third-party cookies beperken, kun je Google Analytics 4 configureren om te vertrouwen op first-party cookies door over te stappen op server-side GA4 tracking. Het koppelen van de tagging server URL aan een custom domain creëert first-party cookies, die betrouwbaarder zijn en een langere levensduur hebben dan third-party cookies.
Het hosten van server-side setups via platforms zoals Google Cloud kan kostbaar en ingewikkeld worden. Daarom geven veel marketeers de voorkeur aan beheerde diensten zoals Stape, dat een gratis tier aanbiedt voor maximaal 10.000 verzoeken en betaalde abonnementen vanaf $20 per maand. Het is de makkelijkste manier om server-side tracking laten opzetten zonder ingewikkeld infrastructuurwerk.
Je kunt GA4-tracking instellen zonder gebruik te maken van cookies, zowel first-party als third-party, door gebruik te maken van Stape's Advanced GA4 tag. Dit maakt puur server-side GA4-tracking mogelijk.
En wat betreft de Facebook-oplossing — Facebook Conversions API en Conversions API Gateway — kan worden gezegd dat het, naast cookies, vertrouwt op gebruikersdata. Met behulp van de gebruikersparameters die je samen met FB CAPI-events meestuurt, koppelt FB events aan gebruikers in hun database. Als gevolg hiervan beschik je over betrouwbaardere data en ben je helemaal niet afhankelijk van cookies. Om het gebruik van FB-cookies te voorkomen, moet je FB-tracking uitsluitend aan de server-side configureren.
Stel dat je een merk in woningverbetering bent. Je kocht vroeger third-party publieksdata over mensen die DIY-blogs bezoeken en retargette hen vervolgens op verschillende platforms via cookies.
In een cookieless setup werkt dit niet meer. Als iemand je site bezoekt zonder in te loggen of toestemming te geven, kun je hem of haar niet one-to-one retargeten. Daarom vertrouwen platforms zoals GA4 of Facebook CAPI nu op server-side setups.
Waarom marketeers overstappen op cookieless tracking
Drie dingen hebben de manier waarop tracking werkt veranderd:
Consumenten begonnen meer privacy en controle te eisen. Ze willen niet zonder het te weten door het hele internet gevolgd worden.
Browsers en techbedrijven zoals Apple en Google reageerden door beperkingen toe te voegen en third-party cookies uit te faseren.
Marketeers hebben nu nieuwe manieren nodig om prestaties te meten en content te personaliseren zonder te vertrouwen op data van derden.
Wat betekent cookieless?
Cookieless betekent het verzamelen van gebruikersdata zonder te vertrouwen op cookies.
Third-party cookies worden gebruikt om de activiteiten van gebruikers op websites bij te houden, waarna de data rechtstreeks naar platforms zoals Google Analytics of Meta wordt gestuurd.
Deze methode wordt 'web tracking' genoemd.
Web tracking resulteert vaak in verloren data, omdat sommige events niet worden geregistreerd vanwege de privacybeperkingen van browsers of ad blockers.
Cookieless tracking werkt zonder gebruikersdata in cookies op te slaan.
In plaats van identificatoren zoals gebruikers-ID of sessie-ID in de browser op te slaan, worden deze gegevens bewaard in een beveiligde backend of rechtstreeks via de cloudserver doorgegeven.
Tools zoals server Google Tag Manager (sGTM) kunnen helpen events te verzenden zonder te vertrouwen op cookies, met behulp van alternatieven zoals URL-parameters of externe ID-systemen.
Deze aanpak vermijdt cookiebeperkingen en verbetert de consistentie van tracking.
Hoe werkt cookieless tracking?
Cookieless tracking werkt op basis van het identificeren en volgen van gebruikers zonder te vertrouwen op cookies, die traditioneel worden gebruikt om gebruikersdata op hun apparaat op te slaan. In plaats daarvan worden alternatieve methoden zoals device fingerprints, server-side tracking en andere technologieën gebruikt om data te verzamelen en te verwerken.
Bij server-side tracking wordt de trackingcode uitgevoerd op de server in plaats van in de browser van de gebruiker. Dit betekent dat het apparaat van de gebruiker geen trackingdata hoeft op te slaan en de tracking volledig aan de serverkant plaatsvindt.
Server-side tracking kan op verschillende manieren worden geïmplementeerd, waaronder:
- Event tracking. Events zoals paginaweergaven, klikken en het indienen van formulieren kunnen aan de server-side worden bijgehouden. De trackingdata kan vervolgens worden opgeslagen in een database of worden verzonden naar een externe analyseservice.
- Serverloganalyse. Serverlogs bevatten informatie over elk verzoek dat aan een website wordt gedaan, inclusief het IP-adres van de gebruiker, de user agent en andere data. Deze informatie kan worden geanalyseerd om gebruikersgedrag bij te houden en rapporten over websiteverkeer te genereren.
- API tracking. API's kunnen worden gebruikt om gebruikersgedrag op platforms van derden bij te houden, zoals sociale media of mobiele apps. De trackingdata kan naar de server worden gestuurd en verwerkt worden via server-side code.
Stape heeft een volledige lijst van platforms die server-side tracking ondersteunen.
Om server-side tracking zonder cookies te implementeren, is het essentieel om elke trackingvendor uitsluitend aan de server-side te configureren. Deze aanpak zorgt voor straktere controle over de informatie die elke vendor instelt en verzamelt.
De standaardinstellingen van platforms zoals Google Analytics 4, Facebook en TikTok werken bijvoorbeeld met alleen web (client-side) tracking, maar dit laat vaak hiaten in de data achter. Om nauwkeurige en volledige inzichten te krijgen, passen de meeste bedrijven een hybride aanpak toe die web- en server-side containers combineert. In GA4 is deze aanpak bijzonder relevant nu meer marketeers overstappen op cookieless tracking GA4 om de afhankelijkheid van browsercookies te verminderen. Terwijl webpixels nog steeds data kunnen verzamelen, helpt server-side tracking dataverlies door ad blockers, ITP en andere browserbeperkingen te overbruggen – waardoor het de sleutel is tot betrouwbare, privacyconforme analyses. Je kunt een cookieless setup ook combineren met marketing mix modeling om budgetten te plannen en resultaten te voorspellen.
Met pure server-side tracking heb je één datastroom die gebruikers- en eventdata naar de server-side container stuurt, wat bijvoorbeeld webhooks van je CMS of CRM kunnen zijn. Vervolgens bepaal je binnen de server-based Google Tag Manager-container welke informatie wordt doorgegeven aan je analytics- en marketingplatforms.
Hoofdstappen voor de implementatie van cookieless tracking
Cookieless tracking kan er anders uitzien afhankelijk van je setup, maar de kernprincipes blijven hetzelfde.
Dit is wat de meeste cookieless configuraties bevatten:
Sla cookies volledig over
Vertrouw niet op browsercookies om gebruikers- of sessiedata op te slaan.
Gebruik in plaats daarvan een backend-opslag zoals Stape Store. Voor cookieless GA4 tracking betekent dit het opslaan van waarden zoals client_id, session_id en first_visit rechtstreeks in je backend.
Maak je eigen identificatoren aan
Om browserevents te koppelen aan opgeslagen data, heb je een consistente identificator nodig.
Dit kan worden gedaan met fingerprinting of Stape User ID.
Sla click IDs op in een externe database
Leg belangrijke click IDs zoals fbclid vast via de URL op de landingspagina en sla ze op in je backend. Dit helpt platforms zoals Meta conversies te koppelen aan de juiste advertentieklikken, zelfs zonder cookies.
Wat zijn hashed ID's?
Sommige platforms gebruiken gehashte identificatoren wanneer cookies worden geblokkeerd. Dit betekent doorgaans het combineren van IP, user agent en URL om een unieke ID te genereren die aan de server-side wordt opgeslagen.
Deze methode kan werken, maar het is een eenrichtingssysteem. Je kunt gebruikersprofielen later niet verrijken of bijwerken. Tools zoals server GTM en Stape Store geven je meer flexibiliteit om identificatoren te beheren, events te koppelen en gebruikersdata compliant te houden zonder vast te zitten aan hashing.
Vergelijking van cookieless tracking-methoden per criterium
| Server-side tracking | Data layer | Session storage | Local storage | |
| Gebruiksscenario's | Gevoelige data voor lange tijd opslaan | Realtime dataopslag | Events bijhouden en tijdelijk opslaan (paginaweergaven, klikken) | Events persistent bijhouden |
| Duurzaamheid van data | Zo lang als nodig (afhankelijk van serverconfiguratie) | Zolang de gebruiker op de pagina is | Zolang een sessie loopt | Tot data handmatig wordt gewist |
| Limieten voor datagrootte | Geen limieten | Niet vast, maar gebruikt voor kleine datasets | 5 MB per origin | 5 MB per origin |
| Locatie | Server-side (een server die je zelf bezit en beheert) | Client-side (browser van de gebruiker) | Client-side (browser van de gebruiker) | Client-side (browser van de gebruiker) |
| Beveiliging | De veiligste in vergelijking met andere methoden | Kwetsbaar voor client-side aanvallen (bijv. Cross-Scripting) | Kwetsbaar voor client-side aanvallen (bijv. Cross-Scripting) | Kwetsbaar voor client-side aanvallen (bijv. Cross-Scripting) |
Cookieless tracking-methoden uitgelegd
Server-side tracking: veilige en nauwkeurige dataverzameling
Het voordeel van server-side tracking is dat alle gebruikersdata eerst naar de server wordt gestuurd en daarna wordt overgedragen aan trackingplatforms (zoals Google Tag Manager) en externe vendors (bijv. Google Analytics). Dergelijke methoden voor dataverwerking en -distributie helpen ad blockers en browserbeperkingen te omzeilen. Server-side tracking helpt ook bij naleving van GDPR- en CCPA-regelgeving.
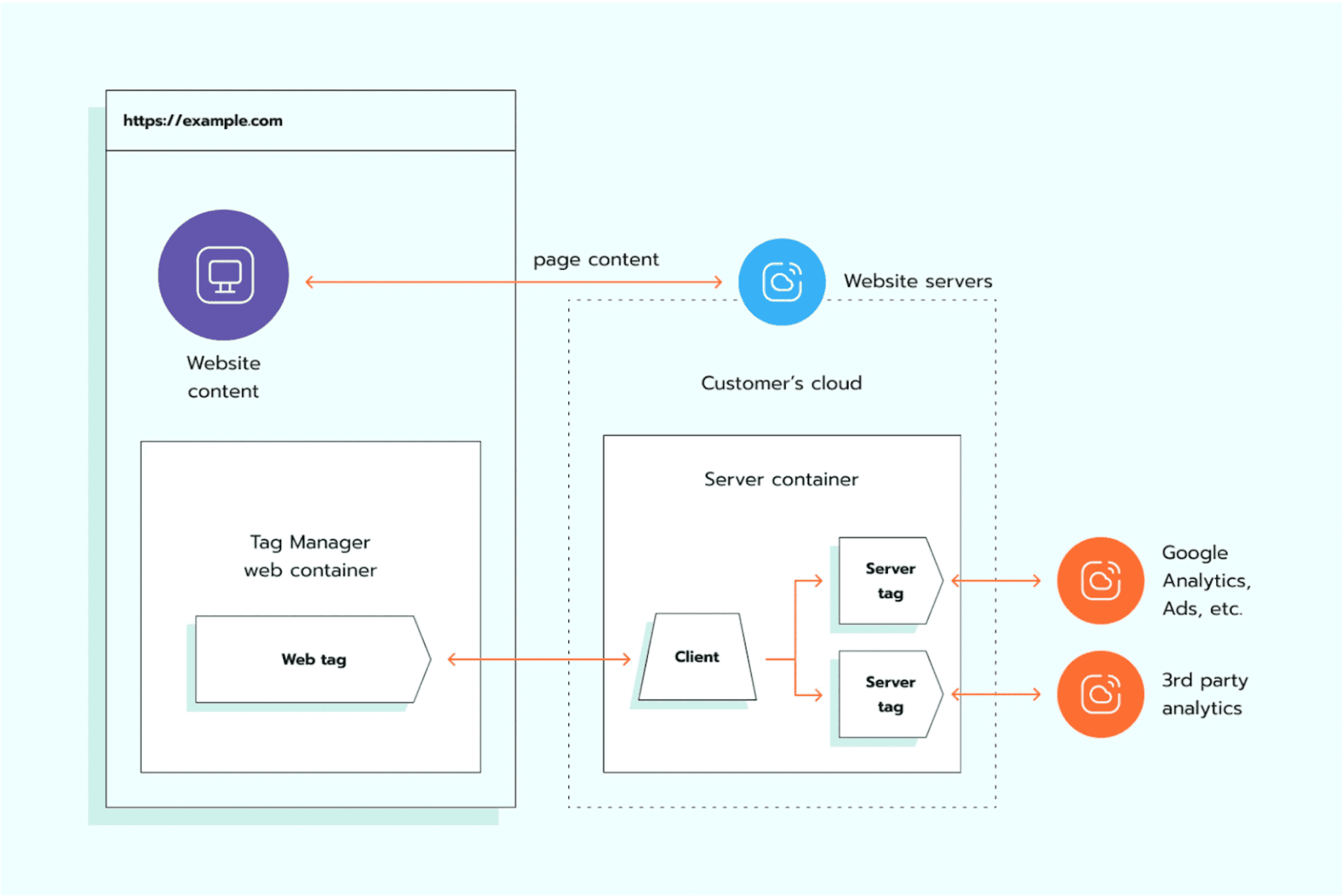
Een ander voordeel van server-side tracking is de hogere controle over verzamelde data, omdat alle data op je eigen servers wordt verwerkt in plaats van aan de client-side (browsers van gebruikers) te worden behandeld. In tegenstelling tot client-side methoden zoals Local en Session storage biedt deze aanpak verbeterde beveiliging, waardoor het een betere keuze is voor het beheren van gevoelige informatie.
Hoe begin je met server-side tracking?
Ten eerste moet je een hostingprovider kiezen voor de server GTM-container. Een populaire optie is het gebruik van Google Cloud Platform. We raden aan Stape te overwegen als hostingprovider en oplossingsplatform voor server GTM. Stape heeft veel voordelen ten opzichte van GCP, waarvan bedrijven van alle groottes en typen kunnen profiteren.
| Stape | Google Cloud Platform |
| Gratis abonnement voor 10.000 verzoeken per maand | Prijs begint bij $120/maand |
| Breed aanbod aan abonnementen voor websites met veel verkeer om te voorkomen dat je te veel betaalt ($20 - $300/maand) | Voor websites met meer verkeer kan de prijs oplopen tot $240-$300 per maand |
| Geen extra kosten als je een betaald abonnement hebt | Logs kosten een extra $100 voor 500.000 verzoeken |
| Verscheidenheid aan oplossingen voor sGTM (power-ups, tags, variabelen) |
Ten tweede moet je een server-side container aanmaken en configureren. Als je al web GTM hebt gebruikt, zul je waarschijnlijk geen moeite hebben met het instellen ervan, omdat de interface en functies vergelijkbaar zijn.
Daarna kun je oplossingen en power-ups toevoegen en alle tracking instellen die je nodig hebt voor je bedrijf.
Data layer: effectieve realtime dataopslag
De data layer als cookieless oplossing werkt voor gevallen waarbij je lichte data moet verzamelen (zoals UTM-parameterdata) waarvoor geen extra beveiliging nodig is. Anders raden we aan server-side tracking te gebruiken, wat beter is voor grote datasets en gevoelige data.
De data layer is een methode voor het tijdelijk opslaan van realtime data. Wanneer een gebruiker je website bezoekt, kun je data van hen vastleggen en tijdelijk opslaan in de data layer. Dit gebeurt voordat toestemming wordt verleend. Na de toestemming van de gebruiker (klikken op cookietoestemmingsbanners) breng je data over naar analysetools zoals Google Analytics 4.
Het gebruik van een data layer voor cookieless tracking heeft een nadeel ten opzichte van server-side tracking of local storage: de data wordt opgeslagen zolang de sessie loopt. De verzamelde data is echter toegankelijk voor de tags en scripts die je gebruikt.
Hoe begin je met de data layer?
Je moet de data layer initialiseren (als die nog niet bestaat).
| Gerelateerd: End-to-end gids over data layer in Google Tag Manager – dit artikel is nuttig als je nog niet met de data layer hebt gewerkt. |
Vervolgens moet je het vastleggen van data instellen (bijvoorbeeld UTM-parameters uit de URL) en deze tijdelijk opslaan in de data layer die je hebt aangemaakt. Zodra de gebruiker toestemming geeft (als een trigger), moet het script de benodigde data vinden en overdragen naar de analysetool.
Je moet het script zelf schrijven of een ontwikkelaar vragen dit te doen.
Session storage: voor specifieke data binnen een sessie
Session storage is een goede methode als je data wilt verzamelen die alleen voor de duur van de sessie wordt opgeslagen. Dit soort data omvat paginaweergaven of knokklikken.
Een voordeel van session storage is hoge privacy: de data wordt gewist zodra de gebruiker een sessie beëindigt. Deze functie verhindert echter dat je data lange tijd opslaat, zoals bij server-side tracking of local storage.
Hoe begin je met session storage?
De web storage API laat je werken met de session storage van de browser. Om deze methode toe te passen, moet je een script gebruiken. De JavaScript-code moet eerst het aantal keren van een bepaald event ophalen of initialiseren (bijv. paginaweergave of klik op een knop), vervolgens het aantal events verhogen en opslaan in session storage.
Local storage: persistent data bijhouden over sessies heen
In tegenstelling tot session storage kan local storage data bijhouden en opslaan over meerdere sessies. Het is echter beter om deze methode te gebruiken voor niet-gevoelige data.
Local storage wordt doorgaans gebruikt om data bij te houden en op te slaan, zoals paginataal of lay-out om gebruikersvoorkeuren op je website te bepalen, het aantal transacties bij te houden of events te tellen (klikken, paginaweergaven). Het is ook een effectieve manier om het aantal terugkerende gebruikers te achterhalen (met behulp van een User ID); een dergelijke functie kan nuttig zijn als je merkbekendheid opbouwt.
Hoe begin je met local storage?
Local storage maakt, net als session storage, deel uit van de web storage API, zodat je ermee kunt werken via de API. De werkwijze is vergelijkbaar met session storage; bij local storage moet je het script gebruiken om data lokaal te verzamelen en op te slaan.
7 Belangrijke cookieless tracking-oplossingen voor 2026
De volgende lijst richt zich op tools die professionals gebruiken om attributie, analyses en budgetbeslissingen werkend te houden met minder cookiedata. Gebruik het als shortlist wanneer je bepaalt wat je bovenop je huidige setup wilt toevoegen.
- Stape
- Ruler Analytics
- Google's Meridian
- Meta's Robyn
- TWIPLA
- Matomo
- Fathom
Stape
Stape is een cookieless tracking-optie die een cloudserverlaag aan je setup toevoegt. Events beginnen nog steeds op de website, maar gaan via de cloudserver voordat ze naar analytics- en advertentieplatforms worden gestuurd. Dit helpt signalen stabiel te houden.
Stape geeft je controle over welke data wordt verzonden en waar die naartoe gaat. Je kunt events verrijken met backenddetails, zoals orderstatus, restitutie-informatie, productmarge of een CRM-klant-ID. Dit houdt attributie en rapportage consistent wanneer browsertracking wegvalt.
Ruler Analytics
Ruler richt zich op attributie wanneer identifiers op gebruikersniveau en cookies niet betrouwbaar zijn. Het combineert deterministische meting waar mogelijk met cookieless methoden zoals probabilistische attributie en marketing mix modeling. Deze aanpak helpt je een overzicht te houden van welke kanalen en campagnes omzet genereren, zelfs wanneer je niet voor elke gebruiker op een volledig klikpad kunt vertrouwen.
Een praktisch gebruiksscenario zijn budgetbeslissingen over kanalen heen wanneer conversies plaatsvinden na meerdere bezoeken. Ruler kan signalen zoals vertoningen en andere platformdata gebruiken om impact te modelleren wanneer directe tracking beperkt is. Het is geschikt als attributie je grootste pijnpunt is en je rapportage nodig hebt die stabiel blijft naarmate browserbeperkingen toenemen.
Google's Meridian
Meridian is een marketing mix modeling-aanpak die is ontworpen om te meten hoe marketingactiviteit resultaten beïnvloedt zonder afhankelijk te zijn van cookies. Het werkt door kanalenimpact te modelleren op basis van historische prestaties en media-inputs, in plaats van gebruikers-ID's. Dit maakt het nuttig wanneer je een kanaaloverzicht nodig hebt dat beschikbaar blijft, zelfs wanneer trackingdata onvolledig is.
Het is geschikt als je een meetlaag wilt die kanalen kan omvatten die nooit sterke cookie tracking hadden, zoals offline media. Het helpt ook wanneer je een planningmethode nodig hebt voor bestedingsallocatie over kanalen. Beschouw het als een modelleringslaag die naast je trackingsetup staat, niet als vervanging voor event tracking.
Meta's Robyn
Robyn is een andere marketing mix modeling-tool die zich richt op het meten van advertentie-impact in de loop van de tijd met behulp van machine learning. Het is ontworpen voor teams die voldoende historische data hebben om resultaten over kanalen en campagnes te modelleren. Het helpt de vraag te beantwoorden "wat heeft de resultaten bewogen" zonder gebruikersniveau-cookies nodig te hebben.
Robyn is zinvol als je een onafhankelijke modelleringscheck naast platformrapporten wilt. Het is ook nuttig voor langere verkoopcycli waarbij directe attributie fragiel wordt. Je hebt nog steeds schone inputs nodig, dus de kwaliteit van je bestedings- en resultatendata is belangrijker dan je cookiedekking.
TWIPLA
TWIPLA is een cookieless webanalysetool die heatmaps en sessie-opnames bevat. Het helpt je te zien hoe bezoekers door belangrijke pagina's navigeren wanneer cookies beperkt zijn, zodat je nog steeds frictiepunten in je funnel kunt identificeren.
Gebruik TWIPLA wanneer je meer wilt dan alleen verkeersaantallen. Het geeft je gedragsdata waarop je je marketingbeslissingen kunt baseren.
Matomo
Matomo is een volledig analyseplatform dat tracking zonder cookies ondersteunt. Het biedt basisfunctionaliteiten zoals paginaweergaven, bronnen en events, zonder te vertrouwen op cookies voor identificatie.
Kies Matomo wanneer je een zelfbeheerde analysebasislijn wilt die consistent blijft naarmate cookieregels aanscherpen. Het werkt goed naast server-side tracking, omdat het zich richt op on-site rapportage, niet op advertentieplatformsattributie.
Fathom
Fathom is een privacygerichte webanalysetool gebouwd rondom first-party meting. Het is ontworpen om kerninzichten over je site te bieden, zoals verkeersbronnen en betrokkenheid. Het is geschikt voor teams die schone websiteanalyses willen met een minimale data-footprint.
Fathom werkt goed als vervanging voor cookie-intensieve on-site analyses wanneer je voornamelijk content- en acquistierapportage nodig hebt. Het is ook nuttig wanneer juridische en privacyverwachtingen bepalen wat je kunt verzamelen. Combineer het met een MMM-tool als je diepgaandere campagnemeting nodig hebt.
FAQs
Is toestemming vereist voor cookieless tracking?
Vaak wel.
In de EU vereisen GDPR-regels toestemming van gebruikers als je persoonsgegevens verzamelt, zelfs als je geen cookies gebruikt. Dit omvat IP-adressen, e-mailadressen en alle identificatoren die aan een persoon kunnen worden gekoppeld.
Sommige landen zoals Denemarken, België en Duitsland verbieden alle cookies (zelfs functionele) zonder expliciete toestemming. Van deze strengere regels wordt verwacht dat ze zich verspreiden binnen de EU onder de aankomende ePrivacy-verordening.
In de VS variëren de regels per staat. Sommige, zoals de CCPA van Californië, richten zich meer op transparantie en het geven van de mogelijkheid aan gebruikers om zich af te melden.
Controleer altijd bij je juridisch team wat van toepassing is in jouw regio en hoe je setup omgaat met gebruikersdata.
Wat moeten marketeers doen met cookieless tracking?
Nu cookies minder betrouwbaar worden, hebben marketeers een nieuwe aanpak nodig om data te verzamelen en resultaten te meten.
Hier is waar je je op moet richten:
- Vertrouw niet alleen op browsercookies voor tracking.
- Gebruik first-party data waar mogelijk en sla deze op buiten de browser.
- Stel server-side tracking in om te controleren hoe data wordt verzameld, verwerkt en gedeeld.
- Richt je op betekenisvolle signalen rechtstreeks van je site, niet van scripts of netwerken van derden.
- Zorg ervoor dat je setup voldoet aan lokale privacywetgeving.
Zijn tracking cookies illegaal?
Niet precies, maar ze gebruiken zonder correcte toestemming wel. Wetten zoals GDPR vereisen dat websites expliciete toestemming verkrijgen voordat ze de meeste cookies gebruiken, met name die welke worden gebruikt voor advertenties of cross-site tracking.
Stopt het verwijderen van cookies tracking?
Niet volledig.
Het verwijdert data die is opgeslagen in de browser van de gebruiker, maar tracking kan nog steeds op andere manieren plaatsvinden, zoals via data die via de server van de website wordt verzonden.
Daarom gebruiken veel marketeers nu zowel browser- als servertracking om hun data nauwkeurig en volledig te houden.
Conclusie
Daar heb je het – een overzicht van hoe cookieless tracking werkt en wat het voor je marketingcampagne kan betekenen. We hopen dat deze blogpost je heeft geïnspireerd om tracking zonder cookies te verkennen en die kennis toe te passen in je volgende marketingbeslissing. Met de hulp van Stape kun je je doelgroep bereiken op een niveau dat ze nooit voor mogelijk hadden gehouden.
Dus wacht niet. Begin vandaag nog met cookieless tracking en ontdek hoe het je bedrijf verandert.

Opmerkingen