Comment protéger vos données contre la perte et les fuites
Maryna Semidubarska
AuteurPoints clés
Perte de données et fuite de données : les termes se ressemblent, mais ils ne désignent pas le même problème. L'un concerne des données qui deviennent incomplètes, corrompues, supprimées ou tout simplement absentes. L'autre concerne des données qui parviennent à une personne, un outil ou une plateforme qui n'aurait pas dû y avoir accès. Si vous travaillez avec des données d'analyse, des plateformes publicitaires, des données CRM ou des identifiants clients, vous avez besoin d'une protection sur les deux fronts.
Qu'est-ce que la perte de données ?
La perte de données survient lorsque des informations deviennent indisponibles, incomplètes, corrompues, supprimées ou n'atteignent jamais le système qui en a besoin. En sécurité informatique, cela peut être dû à une erreur humaine, une défaillance matérielle, des droits d'accès mal configurés ou de mauvaises pratiques de stockage. Dans le contexte du tracking, la perte de données se produit aussi lorsque des tags échouent, que les restrictions des navigateurs bloquent des requêtes, que des identifiants disparaissent ou que des événements ne sont pas correctement transmis d'un système à l'autre.
Qu'est-ce qu'une fuite de données ?
Une fuite de données survient lorsque des informations sensibles quittent leur environnement sécurisé et deviennent accessibles à quelqu'un ou quelque chose qui n'aurait pas dû y avoir accès. Cela peut être accidentel — envoyer un fichier à la mauvaise personne — ou technique, comme transmettre des adresses e-mail brutes, des numéros de téléphone, des URLs complètes ou des informations liées à des connexions à des prestataires d'analyse ou de publicité.
Pourquoi protéger vos données ?
Protéger vos données, c'est protéger vos revenus, votre conformité réglementaire, la confiance de vos clients et la qualité de vos prises de décision. IBM indique que le coût moyen mondial d'une violation de données a atteint 4,88 millions de dollars en 2024. Le rapport DBIR 2025 de Verizon a analysé 22 052 incidents de sécurité et 12 195 violations de données confirmées — ce qui illustre à quel point le phénomène est fréquent et sérieux. Pour les professionnels du marketing, les conséquences sont aussi très concrètes : si les données dans GA4, Meta ou Google Ads sont incomplètes ou trop exposées, le reporting devient instable et l'optimisation des campagnes en pâtit.
Types et causes de perte et de fuite de données
Les pertes et fuites de données proviennent d'un nombre limité de schémas récurrents :
- L'erreur humaine : supprimer un fichier, exporter le mauvais rapport, ou copier des données dans le mauvais outil.
- Les malwares et ransomwares, qui peuvent chiffrer, détruire ou voler des données d'entreprise.
- Les mauvaises configurations : stockage cloud accessible à tous, contrôles d'accès insuffisants, ou paramètres de partage non sécurisés.
- Le vol d'identifiants et le phishing, qui permettent aux attaquants d'accéder à des systèmes en paraissant légitimes.
- Les abus internes, où des employés ou des prestataires déplacent des données qu'ils n'auraient pas dû déplacer.
- Une configuration de tracking défaillante : tags cassés, perte d'identifiants lors de parcours cross-domaines, logique de consentement erronée, ou événements d'achat qui n'arrivent jamais à destination.
- Le surpartage vers les prestataires : envoyer à des outils externes plus de données que nécessaire. C'est là qu'un plan clair de gestion des données personnellement identifiables (PII) devient indispensable.
Quel est l'impact de la perte de données sur l'entreprise ?
Le premier impact est financier. Les violations de données coûtent cher à investiguer, corriger, notifier et dont se remettre. Le deuxième impact est opérationnel : les équipes perdent du temps, les rapports se dégradent et les décisions de campagne prennent la mauvaise direction. Le troisième impact est réputationnel : les clients n'apprécient pas les marques qui perdent leurs données ou les transmettent à des tiers sans raison légitime.
Dans le domaine du tracking, les dégâts peuvent rester invisibles pendant des semaines. Une marque peut croire qu'une campagne est peu performante, alors que le vrai problème est des conversions manquantes ou une attribution cassée. Les études de cas Stape l'illustrent clairement. BlueTree a constaté 15 % de perte de données en moins après la mise en place du tracking côté serveur. Un autre client Stape a estimé que près de 30 % de ses données avaient été affectées par les mécanismes de blocage du tracking avant l'implémentation côté serveur. Ce ne sont pas seulement des problèmes de reporting : ils influencent directement l'allocation budgétaire et l'apprentissage des algorithmes publicitaires.
30 % de perte de données en moins pour une marque suisse d'alimentation fraîche pour animaux | Optimize With Data
- Problème : une boutique e-commerce Wix sur mesure rendait les plugins standards inefficaces, entraînant des analytics peu fiables et une perte de données estimée à près de 30 % en raison des restrictions des navigateurs.
- Solution : une configuration de tracking côté serveur sur mesure, utilisant le Custom Loader et Cookie Keeper de Stape pour garantir une collecte de données précise.
- Résultats : l'implémentation a permis de récupérer les signaux de données perdus, entraînant une réduction massive de 86 % du coût par achat sur Meta Ads en seulement un mois.
Perte et fuite de données dans les systèmes de tracking
Les systèmes de tracking perdent des données lorsque les requêtes côté navigateur n'arrivent pas à destination. Cela se produit avec les bloqueurs de publicité, les restrictions de confidentialité des navigateurs, les cookies manquants, les ruptures entre domaines, les redirections, les data layers défaillants ou les event IDs absents.
Les systèmes de tracking laissent fuiter des données lorsqu'ils transmettent trop d'informations à des tiers : valeurs brutes de formulaires, chaînes de requête complètes, identifiants internes liés à une personne, ou identifiants directs comme le nom, le téléphone, l'e-mail, l'adresse, l'IP, les informations de connexion ou les données de santé. C'est pourquoi la minimisation des données est si importante. Si un champ n'est pas nécessaire à l'analyse ou à la mesure publicitaire, il ne devrait pas quitter votre environnement.
Un deuxième problème est la mauvaise qualité des données en entrée. Si les noms d'événements sont incorrects, que des valeurs sont manquantes ou que les formats requis ne sont pas respectés, les données peuvent tout de même arriver à destination — mais rester inutilisables. C'est pourquoi la validation des données doit intervenir avant qu'elles soient stockées, analysées ou transmises.
Comment prévenir la perte et les fuites de données grâce au tracking côté serveur
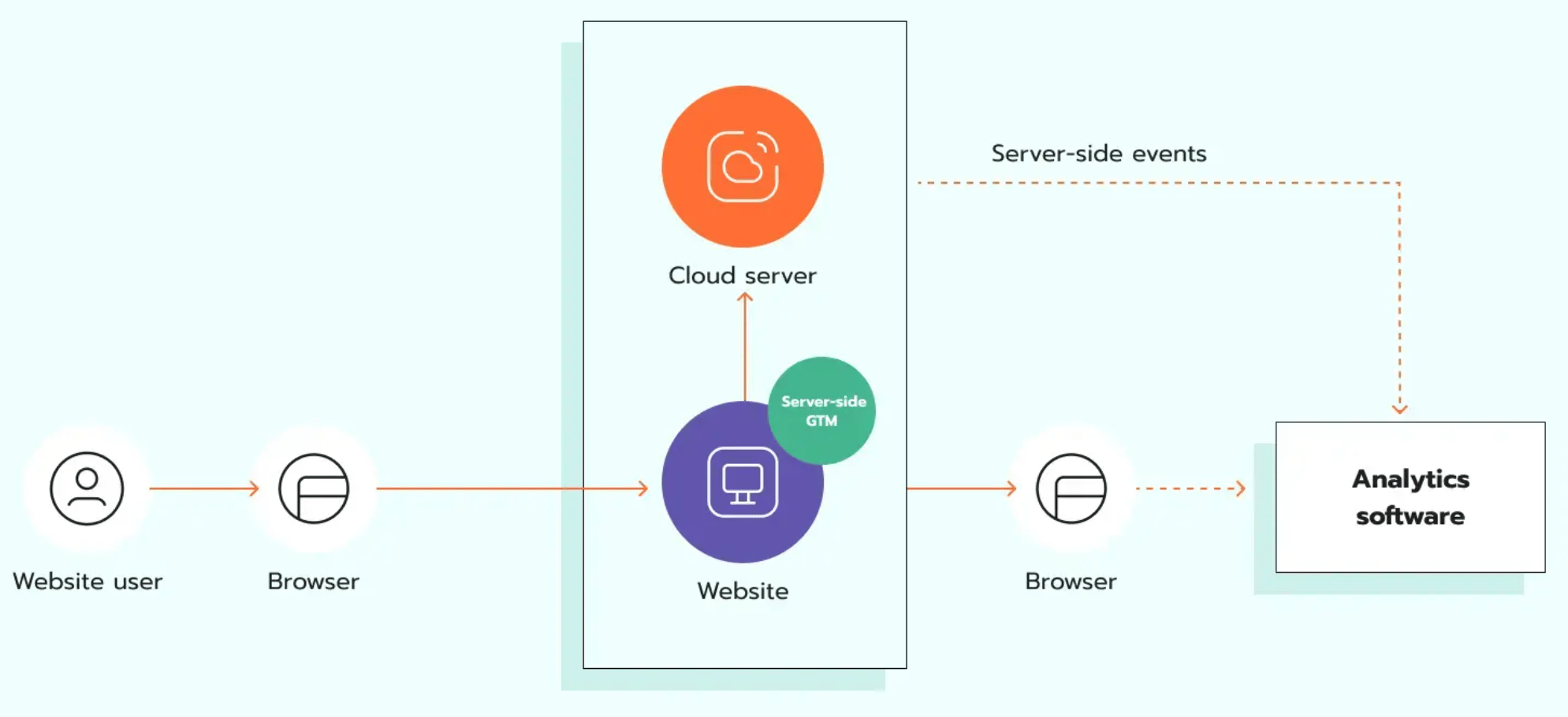
Le tracking côté serveur est efficace parce qu'il ajoute une couche de contrôle entre le site web et la plateforme de destination. Cela ne signifie pas que toutes les données démarrent côté serveur — le tracking commence toujours dans le navigateur. La différence, c'est que la requête peut d'abord transiter par un conteneur Google Tag Manager côté serveur ou par un Gateway dédié, selon le niveau de contrôle souhaité. À l'intérieur de cette couche serveur, vous décidez ce qui est autorisé à sortir, ce qui doit être supprimé et ce qui doit être validé avant d'être transmis.
Un bon processus commence par la cartographie des données :
Définissez quels événements comptent et quelles données chaque événement nécessite réellement.
Listez les plateformes de destination.
Identifiez les champs sensibles.
Envoyez les événements web vers un endpoint serveur hébergé sur un serveur cloud — par exemple, anything.votresite.com.
Validez la requête, supprimez ou hachez les champs sensibles, appliquez les règles de consentement, ajoutez des event IDs pour la déduplication, puis ne transmettez que les données approuvées. C'est également le bon moment pour connecter des données backend — comme une confirmation de commande ou un statut CRM — lorsqu'il existe une raison commerciale réelle et une base légale pour le faire.
Cette couche serveur sert aussi de point de contrôle qualité. Vous pouvez rejeter les événements malformés, bloquer les paramètres inattendus, standardiser les noms de champs et conserver des logs pour le débogage. Cela rejoint directement la question de l'amélioration de la qualité et de l'intégrité des données, car des données sécurisées ne sont pas seulement des données cachées — elles sont aussi complètes, valides et cohérentes.
Des tests restent ensuite indispensables. Vérifiez les requêtes serveur, comparez la structure des événements, examinez le comportement lié au consentement et inspectez ce qui est envoyé à chaque prestataire. En mode aperçu et débogage de Google Tag Manager, confirmez que la requête ne contient que les champs souhaités et que les données utilisateurs sont hachées avant envoi. Après le lancement, la surveillance continue reste essentielle : suivez le flux des événements, le comportement lié au consentement et les données transmises à chaque prestataire. Monitoring par Stape est conçu pour ce type de risque.
Les avantages du tracking côté serveur pour la sécurité des données
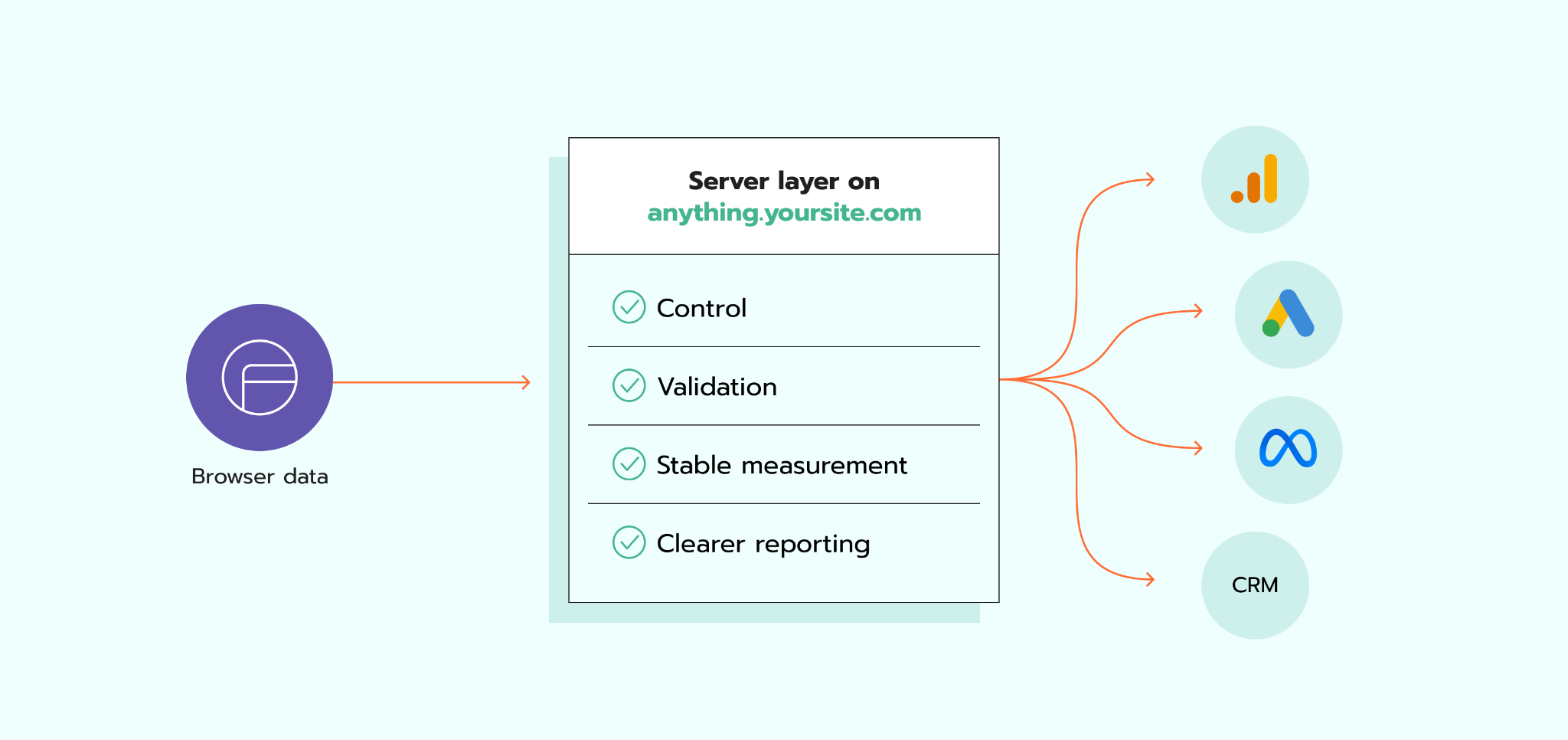
Le premier avantage, c'est le contrôle. Au lieu de nombreux scripts navigateur qui envoient des données de manière autonome, vous disposez d'une couche centrale pour inspecter et gérer ce qui va où. Cela facilite l'application de la minimisation des données, le filtrage des PII et l'alignement des payloads envoyés aux prestataires avec votre politique interne et vos obligations légales.
Le deuxième avantage, c'est la validation. Le tracking côté serveur vous offre un point unique pour vérifier les formats, les champs obligatoires, l'état du consentement et la structure des événements avant que les données n'atteignent GA4, Meta, Google Ads ou un CRM. Cela réduit le risque d'erreurs de reporting silencieuses et de données incorrectes. Cela favorise également une meilleure gestion des données client, car le stockage, le routage et le traitement deviennent plus faciles à gouverner.
Le troisième avantage, c'est une mesure plus stable. Une couche serveur vous donne plus de contrôle sur la façon dont les événements sont vérifiés et envoyés avant d'atteindre GA4, Meta, Google Ads ou un CRM. Cela peut rendre le reporting plus cohérent entre les outils et réduire les écarts causés par les problèmes de navigateur ou les modifications apportées au site.
Le quatrième avantage, c'est un reporting plus clair entre les outils. Lorsque la livraison des événements et la gestion des identifiants sont plus rigoureuses, les plateformes d'analyse et publicitaires reçoivent des données plus complètes. Cela améliore l'attribution, le comptage des conversions et l'analyse marketing — et soutient la qualité des analyses digitales, car l'analyse ne fonctionne bien que lorsque les données collectées sont complètes et cohérentes.
Le tracking côté serveur n'est cependant pas une solution complète de prévention des fuites de données (DLP). Il protège les flux de données marketing et d'analyse, mais ne remplace pas un DLP d'entreprise, la sécurité des terminaux, le contrôle des accès, les sauvegardes ou la gestion des incidents. Toutes ces couches sont nécessaires et complémentaires.
Autres solutions de prévention des fuites de données
Un programme de protection complet nécessite davantage qu'un seul outil.
Commencez par la classification des données. Vous devez savoir ce qui est sensible, où cela est stocké et qui peut y accéder. Appliquez ensuite le principe du moindre privilège, l'authentification multifacteur (MFA), le chiffrement des données en transit et au repos, ainsi que des règles claires de conservation et de suppression. L'ICO et le NCSC insistent tous deux sur des principes comme la minimisation, l'exactitude, la sécurité et la protection des données au repos, en transit et en fin de vie.
Les sauvegardes sont non négociables. La CISA recommande des sauvegardes hors ligne chiffrées et des tests réguliers de leur intégrité et disponibilité. C'est ce qui vous sauve en cas de ransomware, de suppression accidentelle ou de défaillance système.
La formation compte aussi. De nombreuses fuites surviennent parce qu'une personne exporte le mauvais fichier, copie des données au mauvais endroit ou fait confiance à un e-mail de phishing. Des règles claires, des circuits de validation courts et des revues régulières réduisent considérablement ce risque.
Pour les équipes marketing, une couche supplémentaire est le contrôle des prestataires. Vérifiez ce que reçoit chaque outil publicitaire, d'analyse, CRM ou de support. Désactivez les champs non nécessaires, conservez des logs et utilisez des listes d'autorisation. Et revoyez les payloads après chaque modification du site. C'est l'un des moyens les plus simples de prévenir les fuites de données.
Les meilleurs outils de prévention des fuites de données
Il n'existe pas d'outil universel adapté à toutes les entreprises. Le bon choix dépend de votre stack, de vos exigences de conformité et de l'endroit où se situe le risque le plus élevé.
- Microsoft Purview DLP. Un bon choix pour les entreprises utilisant Microsoft 365. Il couvre les applications, les appareils et même les applications IA non managées, avec des contrôles basés sur des politiques dans l'ensemble de l'environnement Microsoft.
- Google Sensitive Data Protection. Adapté lorsque vous avez besoin de découverte, de masquage, de tokenisation, de dé-identification et d'inspection via API dans Google Cloud ou des environnements personnalisés.
- Symantec DLP by Broadcom. Reconnu pour ses capacités de découverte, de surveillance et de conformité dans de nombreux contextes réglementés.
- Forcepoint DLP. Utile lorsque vous souhaitez une couche de politique unifiée couvrant les données au repos, en mouvement et en cours d'utilisation — y compris le web, les e-mails, les uploads SaaS et les terminaux.
- Trellix DLP. Axé sur une visibilité étendue et des contrôles de l'endpoint au cloud, avec application des politiques en temps réel et reporting intégré.
Études de cas
Peak Metrics a lancé un test de 10 jours portant sur 7 032 096 requêtes : le tracking côté serveur a permis de récupérer 20,71 % des requêtes affectées par les mécanismes de blocage du tracking. Pour les événements d'achat, le taux de récupération a atteint 30,67 %. Cela illustre comment une couche serveur peut aider à conserver davantage de données de conversion dans le flux de reporting.
L'étude de cas ROI Assist aborde le même problème sous un autre angle. Leur client présentait un écart de 30 % dans les données de conversion dans Google Ads et GA4. Après migration vers le tracking côté serveur sur Stape, la précision du tracking dans Google Ads et GA4 a atteint 95 %. Cela leur a offert une vision beaucoup plus claire des performances et leur a permis de travailler avec des données de reporting plus complètes.
Jespers Planteskole affichait une précision de tracking inférieure à 80 %. Après l'envoi des données de commande vers GA4 et Meta via un conteneur Google Tag Manager côté serveur, la marque a rapporté un suivi compris entre 97 % et 98 % du chiffre d'affaires. La configuration a également permis de filtrer le trafic interne au niveau du serveur et d'utiliser des scripts auto-hébergés pour répondre aux exigences du RGPD.
Ces cas montrent ensemble comment le tracking côté serveur peut réduire les données manquantes et fiabiliser le reporting.
FAQs
Qu'est-ce que le processus DLP ?
Le processus de prévention des fuites de données comprend cinq étapes. Premièrement, découvrez et classifiez les données sensibles. Deuxièmement, définissez des règles sur qui peut y accéder, les déplacer ou les partager. Troisièmement, surveillez les données en cours d'utilisation, en transit et au repos. Quatrièmement, déclenchez des alertes, bloquez, masquez ou chiffrez lorsqu'une règle est enfreinte. Cinquièmement, analysez les incidents et améliorez les politiques en conséquence.
Quelles sont les 9 règles essentielles de prévention des fuites de données ?
Il n'existe pas de liste officielle universelle intitulée « les 9 règles essentielles ». Un référentiel pratique de neuf règles ressemble à ceci :
- Sachez quelles données vous détenez.
- Classifiez les données sensibles.
- Limitez les accès selon les rôles.
- Utilisez l'authentification multifacteur.
- Chiffrez les données au repos et en transit.
- Validez et minimisez ce qui quitte chaque système.
- Maintenez des sauvegardes hors ligne, chiffrées et testées régulièrement.
- Formez vos collaborateurs et revoyez les accès prestataires.
- Surveillez les logs et mettez à jour les politiques après chaque incident ou changement majeur.
Quelles données peuvent être volées ou divulguées ?
Toute donnée ayant une valeur commerciale ou personnelle peut être volée ou divulguée. Cela inclut les noms, adresses e-mail, numéros de téléphone, adresses postales, données de paiement, données de santé, identifiants de connexion, adresses IP, identifiants clients, contrats, fichiers tarifaires, code source, enregistrements CRM et identifiants d'analyse dès lors qu'ils peuvent être rattachés à une personne.
En définitive, prévenir la perte et les fuites de données est une question de contrôle. Vous devez savoir quelles données existent, qui est autorisé à y accéder, où elles circulent et ce qui doit se passer avant qu'elles ne quittent votre environnement. Le tracking côté serveur s'intègre parfaitement dans cette démarche, car il offre aux équipes marketing et analytics un point dédié pour valider, filtrer et router les données avec davantage de maîtrise.

Commentaires